
Don't rely on a "race to the top"
To make frontier AI safe enough, we need to "lift up the floor" with minimum safety practices

Anthropic has popularized the idea of a “race to the top” in AI safety: Show you can be a leading AI developer while still prioritizing safety. Make safety a competitive differentiator, which pressures other developers to be safe too. Spurring a race to the top is core to Anthropic’s mission, according to its co-founder and CTO.1
Is the race to the top working?
Competitive pressures can lead to some safety improvements.
When models aren’t reliable or trustworthy, customers get upset, and this creates pressure to fix problems. The CEO tweets on a Sunday, “we are working on fixes asap, some today.”
Currently both OpenAI and Anthropic are dealing with trustworthiness issues with their models, unwanted by either company.2 And once one finds a fix, competitive pressure will mount on the other to quickly find a fix as well.
So, does that mean we can count on a race to the top to keep us all safe?
Not really. “Creating pressure to be safer” is different from “Making sure nobody acts unsafely.”
A race to the top can improve AI safety, but it doesn’t solve the “adoption problem”—getting all relevant developers to adopt safe enough practices.
For instance, Anthropic often cites its safety framework as evidence of how a race to the top can work—but Meta didn’t publish their own safety framework until 17 months later. If AI safety is a race to the top, it’s not a very fast one.
To Anthropic’s credit, they have not claimed that a race to the top is sufficient for AI safety, at least not to my knowledge. But media coverage sometimes suggests otherwise3 —perhaps because Anthropic doesn’t have a paired phrase that emphasizes the need for regulation.
It’s an important point, and so it bears saying clearly:
A “race to the top” must be paired with “lifting up the floor.” As AI systems become more capable, it is dangerous to rely on competitive pressures for getting frontier AI developers to adopt safe enough practices.4
In this post, I will:
Define Anthropic’s philosophy of “race to the top” (including an Appendix with detailed excerpts from Anthropic)
Explain why frontier AI safety relies on “lifting up the floor”
Explain why we shouldn’t rely on a “race to the top” being sufficient
Market forces won’t lead to universal adoption of safety practices
The safety practices desired by the market won’t be strong enough to stop catastrophic risks
Describe ways of making a “race to the top” go better, including complementary policies
Defining a “race to the top” in AI safety
Anthropic’s vision of a “race to the top” is to increase pressure on others to be safer: Demonstrate that a frontier AI developer can be reasonably safe while remaining competitive. Use safety as a competitive differentiator if others are unsafe.
(I’ve compiled statements from Anthropic in the Appendix, as I did not find a previous detailed compilation.)
A few central beliefs of the philosophy include:
Leading by example creates industry momentum: By demonstrating that safety and competitiveness can coexist, frontier labs can exert "gravitational pull" on the rest of the industry. This pull can include:
Making one’s safety techniques widely available, such as by publishing research or open-sourcing software, which lowers the cost for others to follow.
Implicitly giving regulators permission to insist on certain safety practices, which have been shown to be attainable and not that costly.
Market incentives5 can cause developers to adopt safety practices: Customers care about safety, at least somewhat. Accordingly, developers building safer AI systems might be rewarded in the marketplace. This market incentive gives other developers reason to adopt similar safety practices, or risk losing customers.
Market incentives can cause developers to innovate on safety practices: Competition can encourage developers to improve upon safety measures, in order to gain brand differentiation and to operate more efficiently (achieving similar safety at lesser costs).
To influence safety at the frontier, you must be building at the frontier. You need to be confronting the frontier’s actual tradeoffs, in order to determine the right practices. Moreover, you’ll yield your influence to other developers if you are not in fact building.
I agree with all of these claims to some extent. (Though I think the “race” framing of “race to the top” leads to some confused concepts—it would be clearer to call this “leading by example” or “competing via safety”.6)
Still, these claims don’t support the argument that ultimately matters: whether we can rely on a race to the top in order to avoid an AI catastrophe. Instead these claims justify something different—why it could be useful for some frontier AI developers to increase pressure on others via safety.
Inciting a race to the top can be a reasonable strategy for a single developer to take to try to make things go better on the margin. I think it is very reasonable for Anthropic to highlight this philosophy in its public communications.
But that doesn’t mean that “race to the top” is a sufficient strategy for the whole ecosystem to make things go well enough.7
Unfortunately, I fear we need much more than a race to the top for that.
Safety requires “lifting up the floor”
AI safety has two central challenges:
1: “Sufficient practices” - Figuring out safe enough ways of training and controlling a model, which might be extremely capable and have goals different from its developers.
2: The “adoption problem” - Getting all relevant developers to take these actions.
It’s not enough to (1) figure out how to manage a superhuman intelligence (itself an incredibly hard problem, which no developer purports to have solved).
You still need to (2) get everyone relevant - i.e., with any chance of developing a superhuman intelligence - to universally adopt these practices.
A fundamental challenge with “race to the top” is that an unsafe frontier AI developer—one that hasn’t fully adopted the safe practices—still poses risk to everyone. Safety is a problem of the weakest link.8
An analogy: improving the safety of nuclear facilities.
Imagine we live in a town with many nuclear powerplants. These facilities can be managed safely, but require effort to do so: Nuclear safety doesn’t just happen by default.
Each powerplant has some incentive to run itself better; the people inside generally do care about powerplant safety (e.g., they could die, they want to be regarded as good stewards). Maybe the government even offers subsidies like tax credits to do safety improvements at the powerplants.
But unfortunately, some powerplant managers decide not to do the improvements. Maybe they think the risk reduction isn’t worth the hassle they’d have to personally incur, or isn’t worth pulling workers off other projects.
Have we reduced some risk by getting some powerplants to become safer? Yup. Have we guaranteed that we won’t still have a horribly destructive outcome? Unfortunately not—a severe incident at one plant in the town is likely to affect everyone.
AI safety is similar: A misaligned AGI is likely to cause harm far beyond the scope of the developer and its customers. One misaligned AGI is one too many.
And we should expect that some frontier AI developers will not choose to adopt sufficiently safe practices, absent being compelled to.
Why should we expect a “race to the top” not to be enough?
Market forces won’t lead to all relevant AI developers embracing safety practices.
Nor will market forces create pressure for practices that are strong enough to contend with catastrophic AI risks (e.g., those from misaligned AGI).
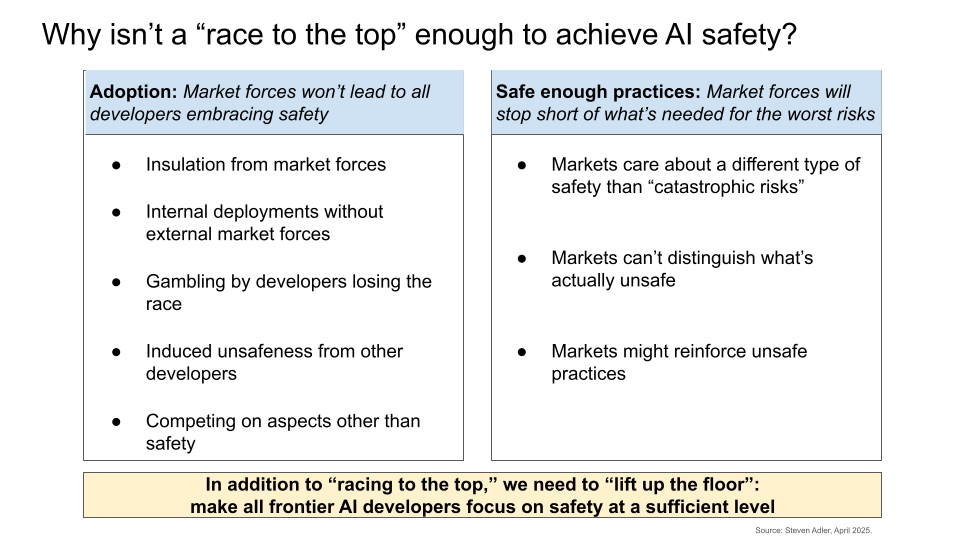
Market forces won’t lead to universal adoption
Some AI developers are extremely insulated from market forces.
Some important players in AI are extremely wealthy and have full company control. If they don’t want to adopt a certain safety practice, it’s ultimately their choice. They might pay some market penalty, maybe, for not adopting this practice—but even so, they can’t be made to do it.
Mark Zuckerberg at Meta is a good example of this: He is Meta’s controlling shareholder, with >50% of voting power. Accordingly, he can take stands on issues, regardless of market pressure. Some shareholders didn’t want Zuckerberg to keep plowing money into the Metaverse, but he thought this was the right long-term bet—and so in went many billions of dollars.9 Yes, there are some pressures on him, like staffing a team, caring about his own wealth via the share price, etc. But Mark Zuckerberg can ultimately make whatever safety choices he wants, no matter what the market says. Elon Musk at xAI is in a similar position.10
Meta has already provided strong counter-evidence to a race to the top: taking 17 months to publish its own safety framework after Anthropic’s release of its Responsible Scaling Policy (RSP). But Anthropic considers safety frameworks to be some of the strongest evidence for race to the top.11 Moreover, Meta continues to be insulated from market forces because its models are “open weights”—freely available for download, with only a nascent business of selling uses via API.12
Perhaps Meta will decide to adopt future safety practices more quickly, or will become less relevant over time13—but we really shouldn’t bank on this.
Some deployments will be internal, not subject to external market forces.
As Apollo Research points out in their recent report, the world’s most powerful AI models will likely be used first by the companies developing them, as part of internal workflows. If the models are useful enough to the developer (e.g., helpful for improving the next version of the model), then internal use might continue indefinitely. The model would not need to be exposed to external customers and related market pressure.
The AI developer of course wants its model to be safe enough for its internal purposes, other things equal—especially once the models are taking on such sensitive tasks. But this is just one consideration among many, and in a race, a developer might be willing to do riskier things.
As I have noted previously, AI developers do not seem to be ready to govern dangerous models internally. For instance, they do not seem to even be monitoring their internal use today (let alone using stronger control measures).
Developers losing a race might gamble in dangerous ways.
Even if developers were all inclined to compete on safety, we need to consider what happens as we approach an ‘endgame’: If a developer appears to be losing in an important race, what is it likely to do?
In many games, if one only cares about winning, the correct play is to take riskier bets. It’s your only shot, and what else do you have to lose?
Consider a football team throwing a Hail Mary pass from deep in their own territory on fourth down: Yeah it’s a gamble—maybe you’ll end up losing by more than if you’d just punted. But playing conservatively won’t get you anywhere, if you’re trying to win.
Even if a race to the top on safety works for a bit, we should expect its dynamics to break down over time. Some players will realize their only hope of winning in AI more generally is to choose a more aggressive strategy.
An unsafe AI developer can induce unsafeness in others.
Some AI developers have adopted carveouts in their safety frameworks, depending on how other developers behave: If one developer seems to be taking more risk than is justified, then others can stop following their own self-imposed rules.14
Even if there is a lot of upward pressure to become safer, this is a powerful downward pull. As Google DeepMind CEO Demis Hassabis has warned, “It remains to be seen whether the race to the top or the race to the bottom wins out.”
Some developers will just compete on different aspects than safety.
Safety being one important differentiator doesn’t mean that it is a decisive differentiator. There will always be some tradeoff for developers and customers to consider: How much more unsafeness is one willing to tolerate, in return for higher capability in a certain domain, lower latency, lower token-cost, etc.
In the extreme, some developers might even lean into very different conceptions of safety as a brand, and reject the dimension along which one is racing to the top (e.g., xAI’s Grok models leaning into a brand of being truthful and anti-woke and so rejecting the safety paradigm of refusals.)15
Market forces will stop short of practices safe enough for catastrophic risk
Market forces care about different types of safety than catastrophic risk.
Whether a model hallucinates facts or can be jailbroken—these are different than whether a model fundamentally wants different goals than its developers do.
You might solve these generally simpler challenges without solving the hardest ones. Maybe the model stops making up facts, but it still subtly undermines your goals and instead tries to steer toward other ones (i.e., is misaligned to your purposes).
It’s helpful for there to be pressure to improve on simpler forms of safety; this does convey useful safety information. If you haven’t stopped your model from getting jailbroken, I don’t trust your safeguards against more complicated attacks.16
But even if the market is satisfied with your model’s safety for its business application, that doesn’t mean you’ve handled all the harder, very important issues.17
Market forces can’t distinguish what’s actually unsafe, in the limit.
Today it is pretty clear that frontier models are misaligned, and so customers can consider this as a selection factor.
In the future, most customers won’t be able to tell.
We need to be prepared for strategic models (“schemers”) that know better than to reveal obvious misalignment to a customer—instead biding time until taking a decisive action.18
We also need to be prepared for hard-to-detect misalignment, in domains where misbehavior can’t be trivially spotted by a human.19
Given this will be beyond customers’ abilities to distinguish, we can’t count on market pressure to push for sufficiently safe practices.
Market forces might reinforce unsafe practices.
In the worst case, market pressure to appear safe might influence a developer to adopt unsafe practices: Perhaps a model is having repeated issues with misalignment. The developer might take steps to train away the undesired behavior, without necessarily fixing the root cause. “Appearing safe” and “being safe” are not the same thing.
This bears repeating: If you catch a model blatantly deceiving you and then teach the model not to do that, it is not clear what you are reinforcing. You might be teaching “don’t deceive me,” or might be teaching “don’t deceive me when you will be caught.”
Some methods of doing this teaching are safer than others.20 And if the less-safe way happens to be quicker, easier, or cheaper, we should expect market forces to push in that direction.
How do we make a “race to the top” go better?
Our goal needs to be not only to (1) figure out strong enough safety practices for powerful AI systems, but (2) to get universal adoption of these practices by relevant developers (overcoming “the adoption problem”).
One idea is to hold racers to certain minimum safety practices during their competition. I’ve written previously about ideas like a minimum testing period for frontier AI, which can stop developers from undercutting one another on safety—making the race safer on the whole. If you go too fast, you can be disqualified, and so you have less reason to take that risk. And if you are too behind on safety, you shouldn’t get to do a last-minute desperation gamble that causes risk to everyone else.
As the stakes get higher, we might even want to pre-qualify who is eligible to enter or stay in the race. A specific policy idea for this—supported previously by OpenAI’s Sam Altman, during testimony to the US Senate—is to have licensing rules for who can develop the leading edge of AI models. This is important if we cross into an era where it’s dangerous to have even trained a particular model, not just to deploy it (internally or otherwise). In this case, governments could revoke certain developers’ license to continue pushing the capability frontier until they have sufficiently caught up on safety practices. (This idea no longer feels politically palatable in the US—e.g., Altman has said that he no longer supports this idea—but I still think it’d be worth doing.21)
Beyond “lifting the floor” of the race via required rules, we can also make sure we’re using a wide range of incentives to get developers to adopt safer practices.
One idea is to provide financial incentives for safety that are not merely about market demand from customers. For instance, governments can offer tax credits or other inducements for investment into safety and security. A similar category of inducement is to use government procurement as one carrot.22 Ideally it’s not just about government wanting to buy the best model on some safety dimension, but actually ruling out certain models as ineligible if they don’t meet particular standards. A further financial incentive is to use liability, as California’s SB 1047 would have (though liability approaches may not be sufficient for catastrophic risks).
Another idea is to make sure that the availability and quality of information about developers’ safety practices are widely known, to enable the intended race to the top dynamic. This might look like requiring more specific transparency reports, at pre-determined cadences and with more standard amounts of information, even if we do not require specific safety practices directly.23
More broadly, journalists and policymakers should push on the frame of a “race to top.” For instance, ask about counterexamples: Why did it take so long for Meta to adopt a frontier safety framework, if a “race to the top” is a true dynamic? Are there safety practices where we can’t afford a 17 month lag between the leader and another developer? What should we do when a frontier AI developer is declining to in fact adopt sufficiently safe practices?
I am glad that at least some AI developers are making safety an important dimension of their brand, openly releasing useful safety techniques, and generally trying to elevate the standard that others adhere to.
Still, it is not enough to merely inspire or to demonstrate what is possible; we need real rules to stop the riskiest developers’ practices from dragging us all down.
Appendix
What has Anthropic said about a race to the top?
I’ve compiled various statements from Anthropic leadership about race to the top. The below should be taken as summarizing and reporting on Anthropic’s statements,24 rather than necessarily endorsing the claims therein.
A race to the top is fundamental to Anthropic’s theory of change and its reason for existence:
Sam McCandlish (CTO and co-founder): “Anthropic's whole reason for existing is to increase the chance that AI goes well, and spur a race to the top on AI safety. …. Please keep up the pressure on us and other AI developers: standard corporate best practices won't cut it when the stakes are this high.”
Anthropic’s values: “We work to inspire a ‘race to the top’ dynamic where AI developers must compete to develop the most safe and secure AI systems. We want to constantly set the industry bar for AI safety and security and drive others to do the same.”
Improving on safety creates a “gravitational force” for others to improve as well:
Jack Clark (co-founder): “[M]arkets are pragmatic, so the more successful Anthropic becomes as a company, the more incentive there is for people to copy the things that make us successful. And the more that success is tied to actual safety stuff we do, the more it just creates a gravitational force in the industry that will actually get the rest of the industry to compete. And it's like, "Sure, we’ll build seat belts and everyone else can copy them." That’s good. That’s like the good world.”
Dario Amodei (CEO and co-founder): “There's also a concept of race to the top, which is that if you do something that looks better, that makes you look like the good guys, it naturally has the effect that other players end up doing the same thing. In fact, having worked at other organizations, something that I learned very much is it's pretty ineffective to argue with your boss or argue with someone who's running an organization. It's their organization. You're not going to negotiate with them to implement your vision, right? That just doesn't work. Whereas if you go off and you do something and you show that it works, and you show that, it is possible to, it is possible to be the good guys, then others will follow.”
RSPs (Anthropic’s frontier safety framework) and interpretability research are areas where Anthropic says it is proud to have caused a race to the top:
Dario Amodei: “A few months after we came out with our RSP, the three most prominent AI companies had one, right? Interpretability research—that's another area we've done it.”
Dario Amodei: “[A]s we’ve done [interpretability research], other companies have started doing it as well. In some cases because they’ve been inspired by it, in some cases because they’re worried that if other companies are doing this, look more responsible, they want to look more responsible too. No one wants to look like the irresponsible actor. And so they adopt this as well.”
Anthropic says it is content to give up its own competitive differentiation in safety if this helps other companies to operate more safely:
Dario Amodei: “When folks come to Anthropic, interpretability is often a draw, and I tell them, “The other places you didn’t go, tell them why you came here.” And then you see soon that there’s interpretability teams elsewhere as well. And in a way that takes away our competitive advantage, because it’s like, “Oh, now others are doing it as well.” But it’s good for the broader system, and so we have to invent some new thing that we’re doing that others aren’t doing as well. And the hope is to basically bid up the importance of doing the right thing. And it’s not about us in particular. It’s not about having one particular good guy. Other companies can do this as well. If they join the race to do this, that’s the best news ever. It’s about shaping the incentives to point upward instead of shaping the incentives to point downward.”
Implicitly, there need to be consequences for being unsafe—not just rewards for being safe:
Dario Amodei: “The hope is that there's this kind of upward race where companies compete not to be the slowest zebra, right, to prevent catastrophes and not to be the ones to be held liable for the catastrophes that happen.”
A race to the top needs to be paired with laws, which ideally can catalyze innovation but may be necessary even if they slow down AI development:
Dario Amodei: “New AI models should have to pass a rigorous battery of safety tests both during development and before being released to the public or to customers. …. [L]egislation could go further [than voluntary commitments] by mandating these tests for all models and requiring that they pass according to certain standards before deployment. It is worth stating clearly that given the current difficulty of controlling AI systems even where safety is prioritized, there is a real possibility that these rigorous standards would lead to a substantial slowdown in AI development, and that this may be a necessary outcome. Ideally, however, the standards would catalyze innovation in safety rather than slowing progress, as companies race to become the first company technologically capable of safely deploying tomorrow’s AI systems.”
“The case for targeted regulation”: “Transparency alone does not guarantee robust policies: companies could simply declare very weak safety and security practices. …. The government can also encourage an RSP “race to the top” by inquiring about and comparing RSPs, learning from the emerging best practices, and holding companies to account if their RSPs are obviously operating beneath the bar set by those practices.”
Anthropic says that customers care about safety and sometimes select Claude because they believe it to be safer:
Daniela Amodei (President and co-founder): “[C]ustomers also really care about safety, right? Customers don't want models that are hallucinating. They don't want models that are easy to jailbreak. They want models that are helpful and harmless, right? — Yeah. And so a lot of the time, what we hear in customer calls is just, "We're going with Claude because we know it's safer. I think that is also a huge market impact, right? Because our ability to have models that are trustworthy and reliable—that matters for the market pressure that it puts on competitors, too.”
To have impact in AI safety, you have to participate in the AI race more generally to confront the tradeoffs:
Dario Amodei: “Where the world needs to get [is]... from "this technology doesn’t exist" to "the technology exists in a very powerful way and society has actually managed it." And I think the only way that's gonna happen is that if you have, at the level of a single company, and eventually at the level of the industry, you're actually confronting those trade-offs. You have to find a way to actually be competitive, to actually lead the industry in some cases, and yet manage to do things safely. And if you can do that, the gravitational pull you exert is so great. There's so many factors—from the regulatory environment, to the kinds of people who want to work at different places, to, even sometimes, the views of customers that kind of drive in the direction of: if you can show that you can do well on safety without sacrificing competitiveness—right—if you can find these kinds of win-wins, then others are incentivized to do the same thing.”
To have impact in AI safety, you need to balance taking the safest approach possible with still providing customer value, because there is a cost to “crying wolf” and you need to bring people along with you:
Jared Kaplan (Chief Science Officer and co-founder): “I think that we ourselves, seeing where the technology is headed, have often thought, "Oh wow, we need to be really careful of this thing," but at the same time we have to be even more careful not to be crying wolf—saying that like, "Innovation needs to stop here.” We need to sort of find a way to make AI useful, innovative, delightful for customers, but also figure out what the constraints really have to be—constraints we can stand behind—that make systems safe, so that it's possible for others to think that they can do that too, and they can succeed, they can compete with us.”
What has been said about safety and customer choice re: models of the past week?
I was inspired to write this post by observing various commentary about Anthropic’s Claude Sonnet 3.7, OpenAI’s o3, and OpenAI’s updated gpt-4o model from April 25th. In particular, given these models’ notable safety issues, how did customers respond?
Here is a roundup of some discussion on these topics (reporting people’s statements, not endorsing).
o3 being deceptive is a barrier to it being a useful product:
Peter Wildeford: “o3 being a giant liar is a huge problem from both a simple product usability standpoint and from an esoteric long-term safety standpoint
If this were an employee, they would get fired”
Some argue that there is an economic incentive to fix alignment issues today, because they disrupt the user experience—but this might not hold into the future:
David Zechowy: “luckily the reward hacking we're seeing now degrades model performance and UX, so there's an incentive to fix it. so hopefully as we figure this out, we prevent legitimately misaligned reward hacking in the future”
Tyler John (responding): “The worry is that if you fix the parts that degrade UX you just get the model to find the cheapest bag of tricks to make the user happy while continuing doing what it's doing, which merely obfuscates rather than solves misalignment”
It is economically worthwhile to invest in some amount of alignment today, but this investment is different than what’s needed for alignment long-term:
Zvi Mowshowitz: “The ‘alignment tax’ has on the corporate margin proven reliably negative. Yes, you pay such a ‘tax’ when you in particular want to impose restrictions on content type, but this enables deployment and use in many contexts.
That’s not where most of the difficult work lies, which is in ensuring the model does what you want it to do, in the ways you’d want to do it. That’s a place everyone is dramatically underinvesting, with the possible exception of Anthropic. Reliability is super valuable.”
Others claim developers will have economic incentive to control alignment, such that the models won’t harm broader society:
Timothy Lee: A lot of safety discourse assumes l companies have weak or no private incentives to prefer well-aligned and controllable models. Which makes no sense. Erratic models will harm the companies that adopt them long before they become dangerous enough to harm society as a whole.
Some customers are switching away from Sonnet 3.7 because it can’t be trusted:
Various tweets quoted in Zvi Mowshowitz’s newsletter:
Ben: we banned 3.7 sonnet at our companyCharles: I have also stopped using 3.7 for the same reasons - it cannot be trusted not to hack solutions to tests, in fact doing so is in my experience the default behavior whenever it struggles with a problem.
Josh You: negative alignment tax, at least in this case.
More on the experience of using Sonnet 3.7:
Jaydan Urwin: “Sonnet 3.7 is like your friend that thinks they're better at writing code when they're drunk. Deletes code that works, forces tests to pass by bypassing them, refactors the entire app. It's fun entertainment but a terrible coding partner.”
Sam Altman on the issues with gpt-4o:
Sam Altman: the last couple of GPT-4o updates have made the personality too sycophant-y and annoying (even though there are some very good parts of it), and we are working on fixes asap, some today and some this week. at some point will share our learnings from this, it's been interesting.
Acknowledgements: Thank you to Dan Alessandro, Drake Thomas, Michael Adler, Pranav Aggarwal, Sam Chase, Rosie Campbell, and Zach Stein-Perlman for helpful comments and discussion. The views expressed here are my own and do not imply endorsement by any other party. All of my writing and analysis is based solely on publicly available information.
If you enjoyed the article, please share it around; I’d appreciate it a lot. If you would like to suggest a possible topic or otherwise connect with me, please get in touch here.
Sam McCandlish (CTO and co-founder): “Anthropic's whole reason for existing is to increase the chance that AI goes well, and spur a race to the top on AI safety. …. Please keep up the pressure on us and other AI developers: standard corporate best practices won't cut it when the stakes are this high.”
For more quotes from Anthropic about “race to the top,” see compilation in the Appendix.
These are instances of a model being misaligned—pursuing goals other than the ones intended by its developers. An example of how their models might behave badly: When you ask models to fix a bug in your code, they shouldn’t cheat by making your code’s tests just ignore the bug. Worse, the models shouldn’t then gaslight you about having done this.
I think Steven Levy’s strong profile of Anthropic underemphasizes the importance of government regulation in Anthropic’s view, eg: “It would seem an irresolvable dilemma: Either hold back and lose or jump in and put humanity at risk. Amodei believes that his Race to the Top solves the problem. It’s remarkably idealistic. Be a role model of what trustworthy models might look like, and figure that others will copy you. “If you do something good, you can inspire employees at other companies,” he explains, “or cause them to criticize their companies.” Government regulation would also help, in the company’s view. (Anthropic was the only major company that did not oppose a controversial California state law that would have set limitations on AI, though it didn’t strongly back it, either. Governor Gavin Newsom ultimately vetoed it.) Amodei believes his strategy is working. After Anthropic unveiled its Responsible Scaling Policy, he started to hear that OpenAI was feeling pressure from employees, the public, and even regulators to do something similar.”
By “frontier AI developers,” I mean the small number of developers training the most capable models in the world—likely just a handful of organizations. For discussion of how to define “frontier AI,” see “Frontier AI Regulation: Managing Emerging Risks to Public Safety.” I’d expect the resultant definition to likely include organizations like Anthropic, Google DeepMind, Meta, OpenAI, and xAI.
Market incentives refer to more than just customer preferences; these incentives also include benefits like gaining more technical talent and dollars of investment. In this piece, I am generally using “market incentives,” “market forces,” and “competitive pressures” synonymously—the system of reward for e.g., having a more capable model or having a safer model.
I prefer to think of “race to the top” as “leading by example” or “competing on safety”, rather than as a “race.”
Two reasons for this preference: (1) This “race to the top” has very different characteristics than the primary “AI race” we normally talk about. (2) Calling it a “race to the top” sounds like a rebuke or redirection (“to the top”) of the primary “AI race”, when in fact the two races can totally coexist.
(1): By the primary AI race, I mean the US and China competing to obtain a decisive strategic advantage in AI, from being the first to reach a certain capability level. For instance, one nation might attain AI that can “recursively self-improve” and beget even stronger AI. That race has a finish line in some sense: being the first to attain the decisive capability level, if this paradigm is correct. Whereas the “race to the top” has no clear finish line or decisive winner—just developers jockeying back and forth on their competitive positioning so long as they are each competing.
(2) Calling it a “race to the top” sounds like a rebuke or redirection (“to the top”) of the primary “AI race”, when in fact the two races can totally coexist. “Race to the top” obscures that the primary AI race is still happening: There is not an either-or choice between “racing on capabilities” and “racing to the top on safety”; both can coexist.
In the auto industry, manufacturers are able to market their cars’ safety as a selling point, but our society has decided that such market-based incentives are insufficient; we rely on governments to set minimum regulatory standards for car safety.
Even if safety is about the weakest link, some AI safety researchers think that the number of relevant AI developers might be very small, particularly if one AI developer can race out to a decisive AI capability advantage over other developers. When many developers are racing in a deadheat, the number of relevant developers is larger.
xAI is a private company, and so it’s less clear to me whether Elon is a fully controlling shareholder in the same way that Mark is at Meta. Still, it’s hard for me to imagine others overruling him without something surprising happening.
Anthropic has said that its Responsible Scaling Policy (RSP) incited other leading labs to have similar frameworks within a few months. This is somewhat true—for instance, OpenAI’s Preparedness Framework came out two months later, though similar ideas were already brewing prior to Anthropic’s release. Demis Hassabis of Google DeepMind has said, “We’ve always had those kinds of things in mind, and it’s nice to have the impetus to finish off the work.” Beyond taking 17 months later (Sept 2023 through Feb 2025), Meta’s framework has been reviewed as pretty lackluster compared to what other labs have (see review here).
Meta still cares about adoption presumably—otherwise why invest in building these models?—but is more insulated from market pressures than a company whose revenue fundamentally depends on its models being purchased. Still, Meta’s strategy might change in the future, which would make the company more subject to market forces: On April 29th, Meta announced that it is beginning a “limited preview” of its models being queryable by API.
Meta’s recent Llama 4 models have not been very well-regarded, and so it is possible that Meta’s importance as a frontier AI player will decrease over the next year or two.
For instance, Google DeepMind’s frontier safety framework says, “[O]ur adoption of the protocols described in this Framework may depend on whether such organizations across the field adopt similar protocols.” OpenAI’s updated Preparedness Framework similarly allows OpenAI to change its safety requirements if another developer is taking certain risks, though describes an important safeguard: “[I]n order to avoid a race to the bottom on safety, we [will] keep our safeguards at a level more protective than the other AI developer, and share information to validate this claim.”
Jailbreaks are a well-known attack—getting the model to disregard a developer’s rules. It is also pretty simple to verify whether a jailbreak succeeded. So if you haven’t solved the simple attack, you probably haven’t safeguarded well enough against more complicated and serious attacks either. (Today, when a new model launches, it is almost always jailbroken nearly immediately, often by one particular X user.) For an overview of different types of AI safety challenges, I find Miles Brundage’s thread helpful.
In some other industries, where customers internalize the risks of an unsafe product—say, in food safety, where customers are the ones to get sick if there’s an issue—companies are more likely to invest an appropriate amount into safety. But in AI safety, the harms of a seriously misaligned model are externalized to a much wider population than just the AI developer’s customers. To use the economics term, the AI companies under-investing in safety is a classic example of market failure.
For an overview of scheming, see Scheming reasoning evaluations.
An important challenge in ensuring a model’s safety is “How do you tell that a model is misaligned, once the model’s work is too complicated for you to evaluate?”
For a discussion of methods you definitely shouldn’t do, see: The Most Forbidden Technique, quoting OpenAI’s research: “We recommend against applying strong optimization pressure directly to the [chains of thought] of frontier reasoning models, leaving [chains of thought] unrestricted for monitoring.” For another approach, see Anthropic’s Putting up Bumpers.
For a paper exploring these ideas, see Frontier AI Regulation: Managing Emerging Risks to Public Safety. For a retraction of the licensing idea, see Sam Altman’s TED interview.
See e.g., suggestion by Miles Brundage.
Standard transparency reports could be a useful norm for many forms of safety, not just catastrophic risks. For instance, both OpenAI and Anthropic have released reports at different points in time on how they have disrupted influence campaigns on their platform: Detecting and Countering Malicious Uses of Claude: March 2025, Influence and cyber operations: an update. This is great to hear, and I believe would be of even more information value if delivered by developers at a routine cadence.
There is a chance of minor transcription errors, particularly around punctuation as some of these quotes are from a video of an Anthropic leadership conversation.
Hi Steven, thanks for writing this. I have some comments, but first I want to say that it’s easy to criticise ideas in this space, and much harder to actually put them forward, so I appreciate you doing that. That said, I do have a few questions:
From the way you’ve written this, it sounds like the ‘outside view’ is that racing to the top is a legitimate theory of change that people are actively relying on. I’d be surprised if that’s true. Even a moderately sceptical reader could spot the flaws you mention. Are people really counting on labs racing to the top as a strategy? What’s your sense of the median view here?
In the ideas section, a few of the proposals didn’t seem to tackle the core problem of adoption. (I’m hoping to write about a supervision-based idea you didn’t mention, and I’d be interested to hear your take on it.) Take the minimum testing period, for example, what prevents labs from lobbying for a shorter period? Couldn’t they just argue that labs in the PRC might catch up, and use that to push for an exemption? If you’ve covered this in the linked post, feel free to just point me to it.
On licensing: who’s actually issuing these licences? From what I gathered, it’s the US government. If that’s right, my main concern is enforcement. Once a licence is revoked, what stops a lab from continuing development anyway? Do we expect the government to be technically competent and well-informed enough to even know it’s happening? And if we imagine scenarios where AI is doing AI R&D, what do licences actually constrain? What does the licence stop?
On liability (sorry not framed as question but thought I’d share my thoughts): yes, it’s politically difficult. But it seems to me the point of liability isn’t that courts will fix things after catastrophic harms happen. Rather, it’s another tool like (licensing or financial incentives) to slow things down beforehand. Whether it actually works in practice is a fair question. I think it’s worth being sceptical, for example: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3563452
On transparency: I agree it matters, but don’t we already have some of this? For instance, model reports and red-teaming from groups like Apollo already show that models can be prompted to scheme. So what do you see as the actual effect of more transparency? What changes, in your view, if we get it?